Definition
Machine learning is a type of artificial intelligence that provides computers with the ability to learn without being explicitly programmed. It has strong ties to statistics and mathematical optimization. Computer scientists design algorithms that can learn from data, usually through types of supervised, unsupervised, and reinforcement learnings. Wikipedia
Typical uses of machine learning, include spam filtering, optical character recognition (OCR), search engines, computer vision, Jeopardy.

General Process
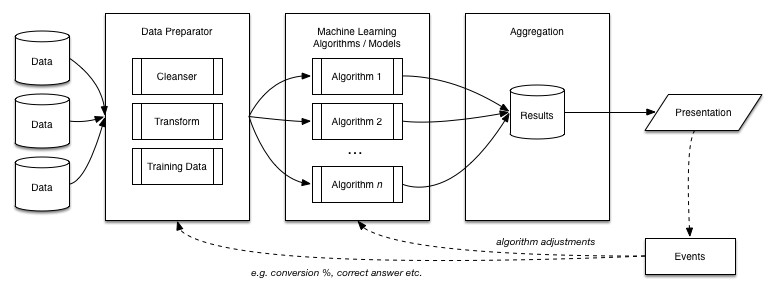
This is an abstracted process in generating intelligence based on incoming data, apply algorithms and models, present and measure events.
UC #1 - Predictive Analytics
Determine patterns and predict future outcomes and trends.
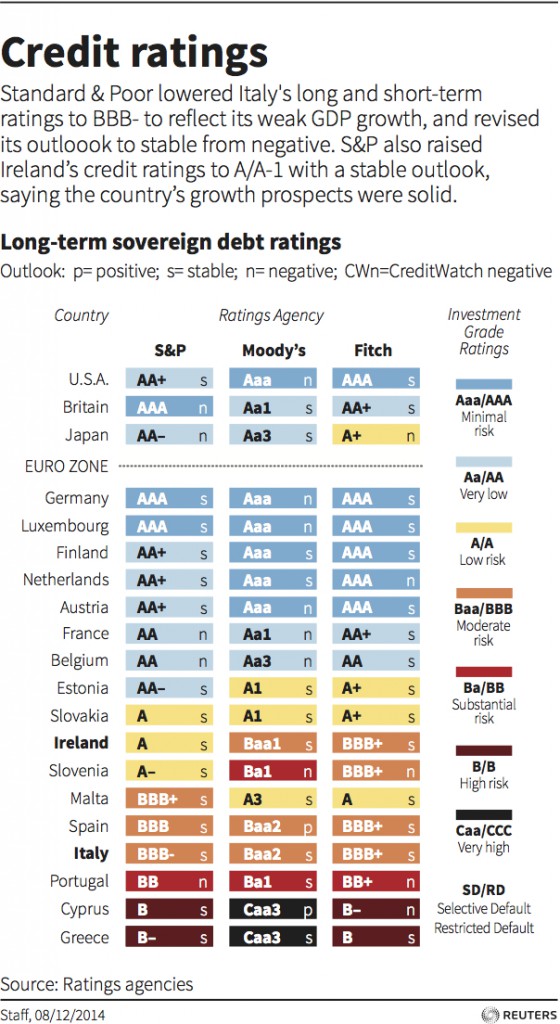
UC #2 - Risk Analysis
Calculate credit ratings, fraud detection, credit scores.

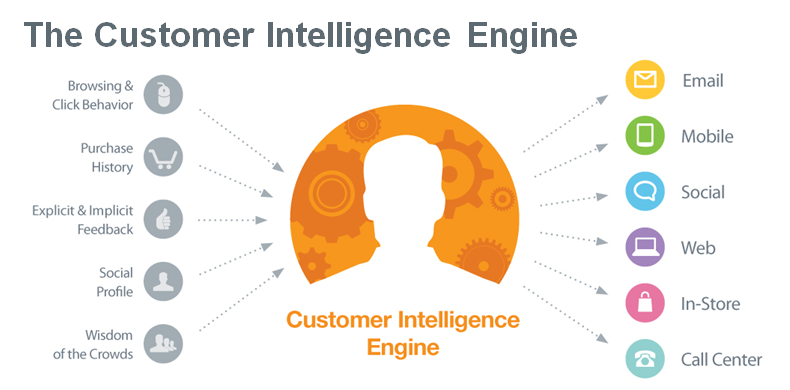
UC #3 - Customer Intelligence
Build deeper and more effective customer relationships.
Approaches #1
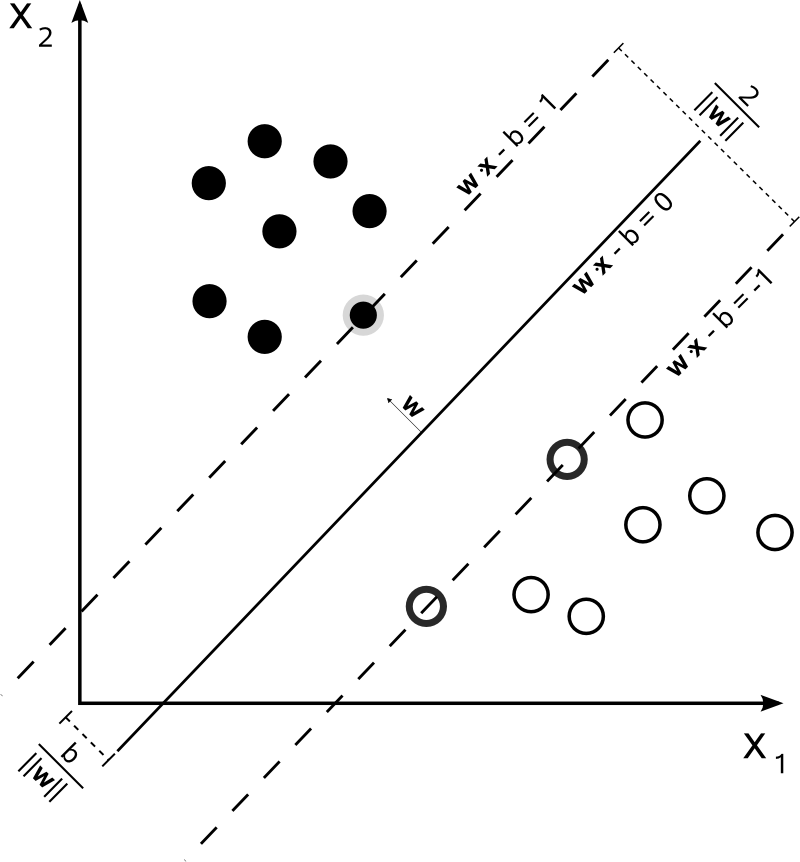
Decision Tree, Association Rule, Inductive Logic Programming, Support Vector Machines, Reinforcement Learning, Similarity and Metric Learning
Approaches #2
Articial Neural Networks, Clustering, Bayesian Networks, Representation Learning, Genetic Algorithms, Sparse Dictionary Learning
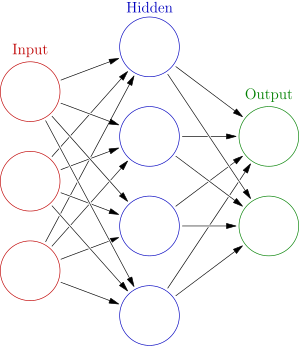
Tools #1 - Traditional Modeling
Traditional business intelligence, data warehousing and data modeling. Supervised learning algorithms can be implemented through traditional BI/DW platforms and tools.

Tools #2 - Apache Mahout

• Machine learning and data mining, written in Java, Scala
• Primarily focused in the areas of collaborative filtering, clustering and classification.
• Algorithms include Collaborative Filtering, Matrix Factorization with ALS, SVD++, Naive Bayes, Random Forest, Hidden Markov Models, k-Means Clustering, Fuzzy k-Means, QR Decomposition etc.
• In April 2014, the Mahout community decided to stop implementing new algorithm in Hadoop MapReduce in favor of Apache Spark.
Tools #3 - Apache Spark™
• Apache Spark™ is a general engine for large-scale data processing.
• Spark runs on Java 6+ and Python 2.6+. For the Scala API, Spark uses Scala 2.10.

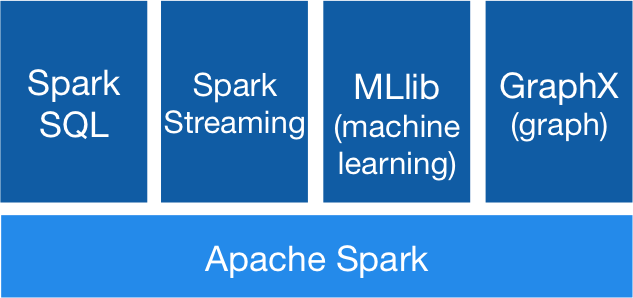
• Spark MLlib supports algorithms including linear models, naive Bayes, decision trees, ALS k-Means, Gaussian mixture, LDA, SVD, FP-growth, stochastic gradient descent etc.
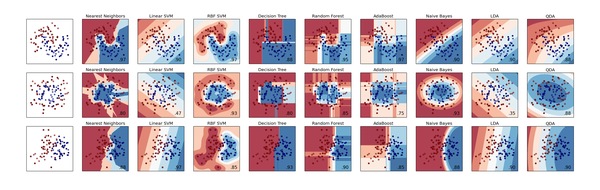
Tools #4 - Scikit-Learn
![]()
• Machine learning in Python, built on NumPy, SciPy and matplotlib.
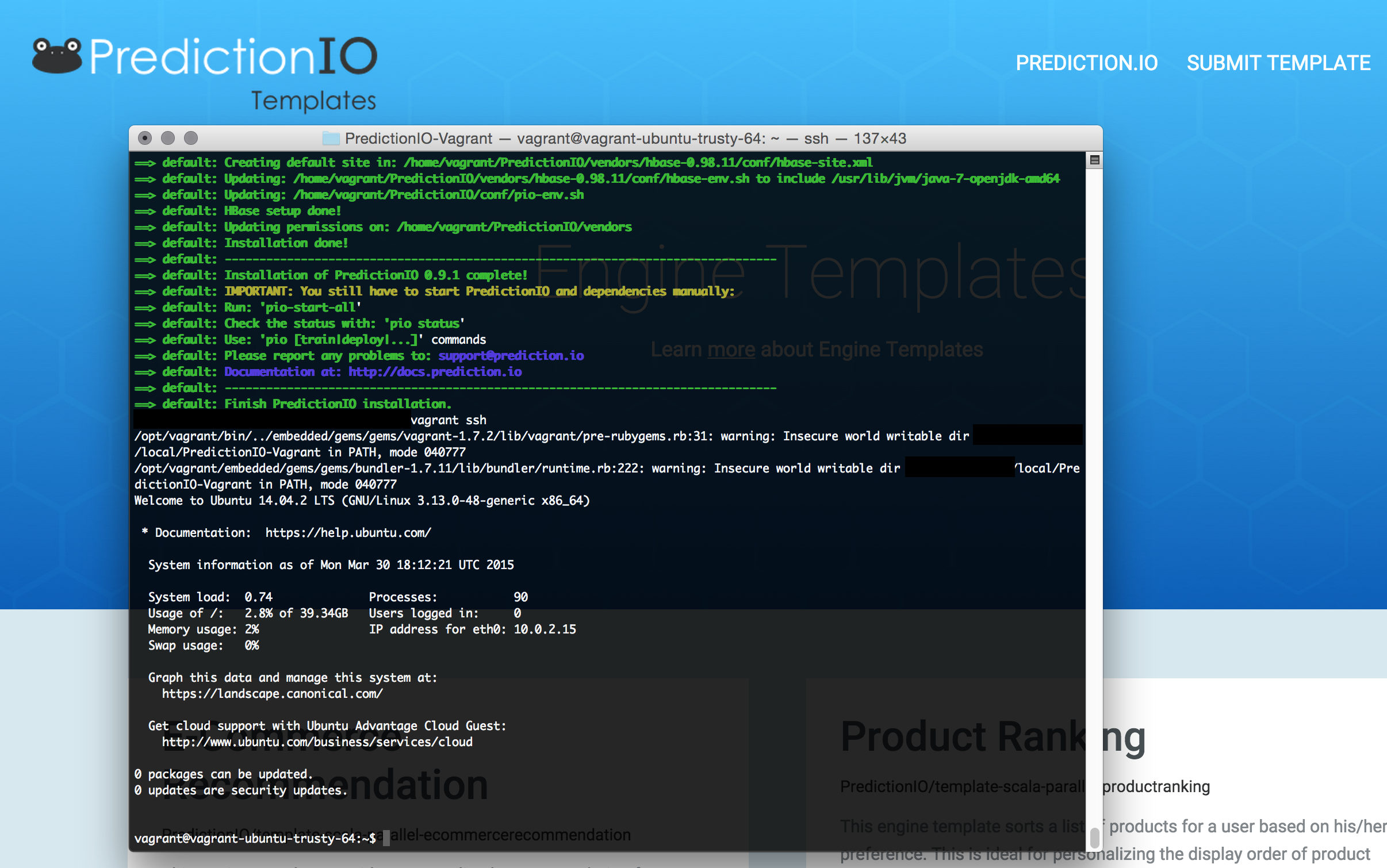
Demo
• Install PredictionIO using Vagrant
• Install one or more templates from templates.prediction.io, such as recommendation
Architecture #1 - Prediction IO
![]()
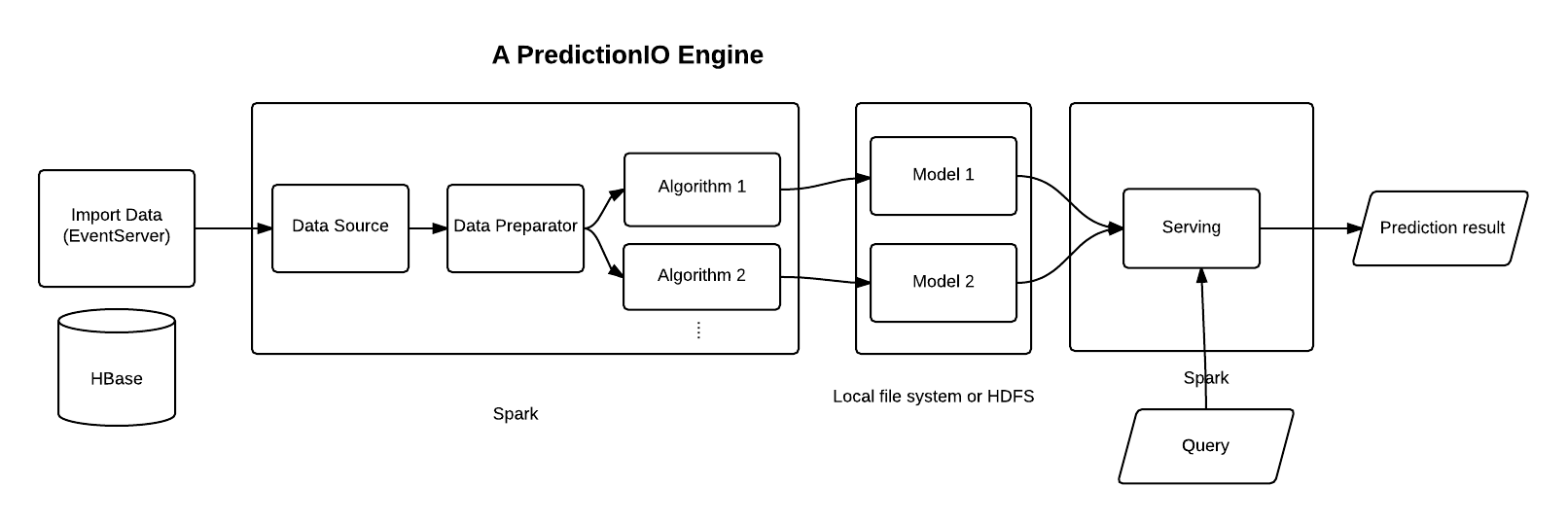
• Apache Hadoop 2.4.0 (if YARN and HDFS), Apache HBase 0.98.6, Apache Spark 1.2.0 for Hadoop 2.4, Elasticsearch 1.4.0
• Version 0.8, the project switched from Hadoop MapReduce to Apache Spark
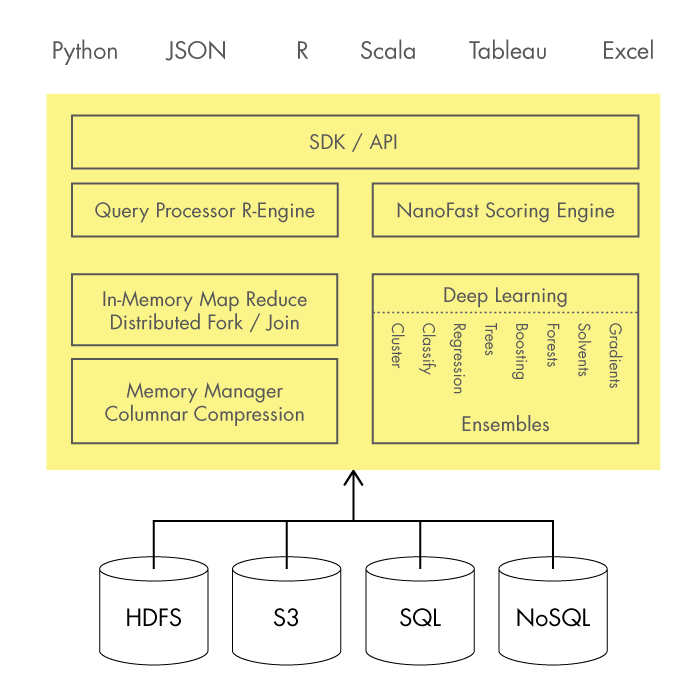
Architecture #2 - H2O
|
H2O is an open source predictive analytics platform. The project supports R, Python, Scala, Java, with a RESTful API. |